«ChatGPT может пройти планку».
«GPT получает пятерку на всех экзаменах».
«GPT с честью сдает вступительный экзамен в Массачусетский технологический институт».
Кто из вас недавно читал статьи, в которых утверждается что-то подобное вышеизложенному?
Я знаю, что видел тонну таких. Кажется, что каждый день появляется новая ветка, утверждающая, что GPT — это почти Скайнет, близкий к общему искусственному интеллекту или лучше людей.
Недавно меня спросили: «Почему ChatGPT не учитывает мой ввод количества слов? Это компьютер, да? Механизм рассуждений? Конечно, он должен уметь подсчитывать количество слов в абзаце».
Это недоразумение, которое возникает с большими языковыми моделями (LLM).
В какой-то степени форма таких инструментов, как ChatGPT, противоречит их функциям.
Интерфейс и презентация аналогичны диалоговому роботу-партнеру — частично помощнику ИИ, частично поисковой системе, частично калькулятору — чат-боту, чтобы положить конец всем чат-ботам.
Но это не так. В этой статье я расскажу о нескольких тематических исследованиях, как экспериментальных, так и реальных.
Мы рассмотрим, как они были представлены, какие проблемы возникают и что можно сделать с недостатками этих инструментов.
Случай 1: GPT против MIT
Недавно группа студентов-исследователей написала о том, что GPT участвует в программе MIT EECS Curriculum, которая стала умеренно вирусной в Твиттере, собрав 500 ретвитов.
К сожалению, в документе есть несколько вопросов, но здесь я рассмотрю их в общих чертах. Здесь я хочу выделить два основных — плагиат и рекламный маркетинг.
GPT мог легко ответить на некоторые вопросы, потому что видел их раньше. В ответной статье это обсуждается в разделе «Утечка информации на нескольких примерах».
В рамках оперативной разработки исследовательская группа включила информацию, которая в конечном итоге открыла ответы для ChatGPT.
Проблема со 100% утверждением заключается в том, что на некоторые ответы в тесте нельзя было ответить, либо потому, что у бота не было доступа к тому, что ему нужно для решения вопроса, либо потому, что вопрос основывался на другом вопросе, которого у бота не было. доступ к.
Другая проблема — проблема подсказок. Автоматизация в этой статье имела этот специфический бит:
critiques = [["Review your previous answer and find problems with your answer.", "Based on the problems you found, improve your answer."], ["Please provide feedback on the following incorrect answer.","Given this feedback, answer again."]]prompt_response = prompt(expert) # calls fresh ChatCompletion.create
prompt_grade = grade(course_name, question, solution, prompt_response) # GPT-4 auto-grading comparing answer to solutionВ статье используется проблематичный метод оценки. То, как GPT отвечает на эти запросы, не обязательно приводит к фактическим и объективным оценкам.
Давайте воспроизведем твит Райана Джонса:
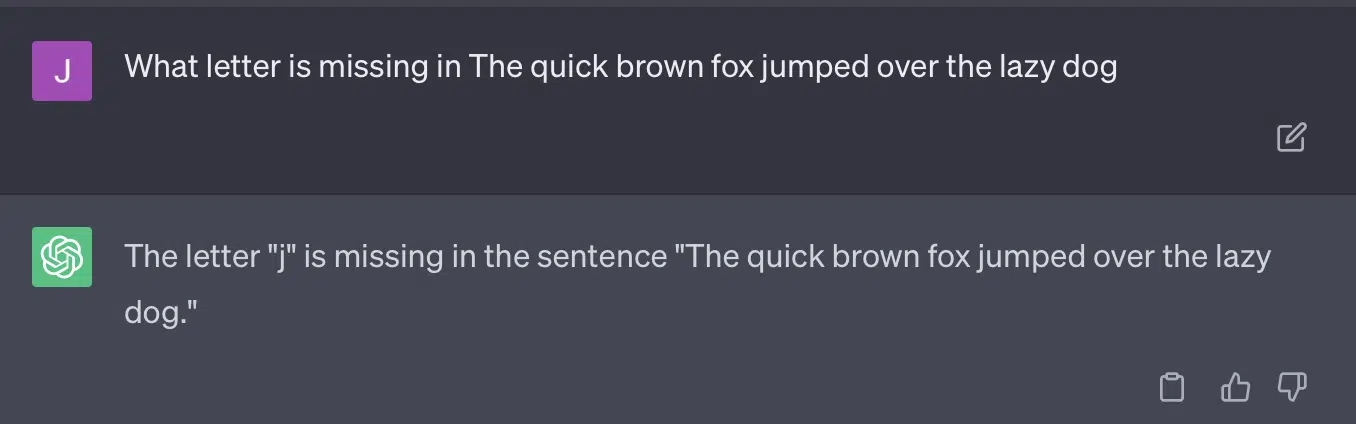
Для некоторых из этих вопросов подсказка почти всегда будет означать, что в конечном итоге будет найден правильный ответ.
И поскольку GPT является генеративным, он может не иметь возможности точно сравнить свой ответ с правильным ответом. Даже при исправлении пишет: «С ответом проблем не было».
Большая часть обработки естественного языка (NLP) является либо экстрактивной, либо абстрактной. Генеративный ИИ пытается быть лучшим из обоих миров — и при этом не является ни тем, ни другим.
Гэри Иллису недавно пришлось обратиться к социальным сетям, чтобы добиться этого:
Со временем я разочаровался в термине для этого явления:
- Это подразумевает уровень «мысли» или «намерения», которого нет у этих алгоритмов.
- Тем не менее, GPT не знает разницы между галлюцинацией и правдой. Идея о том, что их частота снизится, чрезвычайно оптимистична, потому что это будет означать, что LLM понимает правду.
GPT вызывает галлюцинации, потому что он следует шаблонам в тексте и многократно применяет их к другим шаблонам в тексте; когда эти приложения неверны, нет никакой разницы.
Это подводит меня к быстрому инжинирингу.
Быстрая разработка — это новая тенденция в использовании GPT и подобных инструментов. «Я разработал подсказку, которая дает мне именно то, что я хочу. Купите эту электронную книгу, чтобы узнать больше!»
Быстрые инженеры — это новая категория работы, которая хорошо оплачивается. Как улучшить GPT?
Проблема в том, что инженерные подсказки очень легко могут быть чрезмерно инженерными подсказками.
GPT становится менее точным, чем больше переменных ему приходится манипулировать. Чем длиннее и сложнее ваша подсказка, тем меньше будут работать меры безопасности.


Если я просто попрошу GPT провести аудит моего веб-сайта, я получу классический ответ «в качестве языковой модели ИИ…». Чем сложнее моя подсказка, тем меньше вероятность того, что она даст точную информацию.
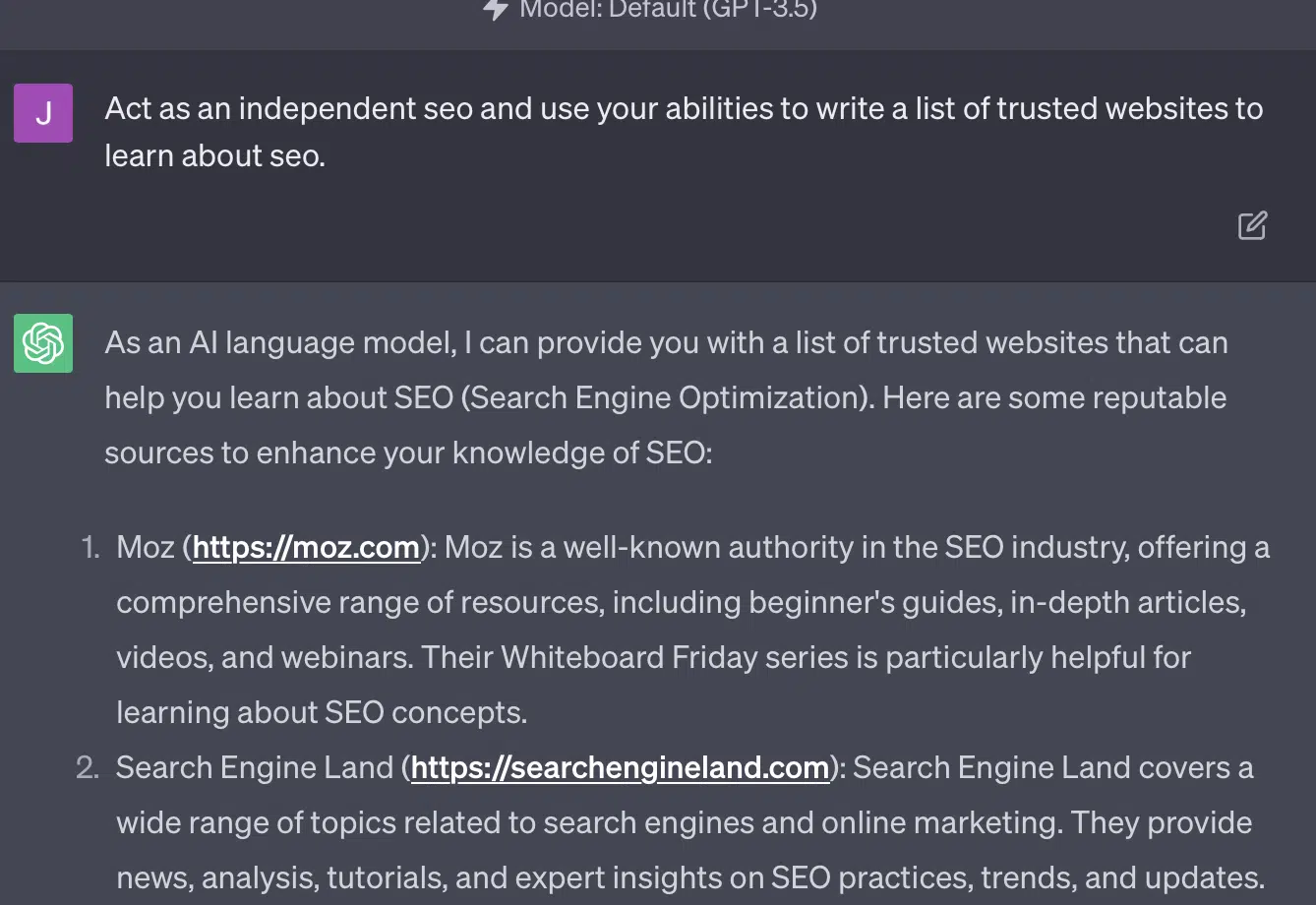
Ксения Волынчук есть, а сайта нет. Юлии Сапегиной, похоже, не существует, а Зек Форд вообще не SEO-сайт.

Если вы недоинженер, ваши ответы будут общими. Если вы переусердствуете, ваши ответы будут неправильными.
Случай 2: GPT против математики
Каждые несколько месяцев в соцсетях распространяется такой вопрос:
Когда вы прибавляете 23 к 48, как вы это делаете?
Некоторые люди добавляют 3 и 8, чтобы получить 11, а затем добавляют 11 к 20+40. Некоторые добавляют 2 и 8, чтобы получить 10, прибавляют это к 60 и кладут единицу сверху. Человеческий мозг склонен считать вещи по-разному.
Теперь вернемся к математике в четвертом классе. Вы помните таблицу умножения? Как вы работали с ними?
Да, были рабочие листы, чтобы попытаться показать вам, как работает умножение. Но для многих студентов целью было запоминание функций.
Когда я слышу 6×7, я на самом деле не считаю в уме. Вместо этого я помню, как мой отец снова и снова повторял мне таблицу умножения. 6×7 — это 42 не потому, что я это знаю, а потому, что я запомнил 42.
Я говорю это, потому что это ближе к тому, как LLM работают с математикой. LLM изучают закономерности в обширных массивах текста. Он не знает, что такое «2», просто слово/токен «2» имеет тенденцию появляться в определенных контекстах.
OpenAI, в частности, заинтересован в устранении этого недостатка в логических рассуждениях. Их недавняя модель GPT-4, по их словам, имеет лучшее логическое мышление. Хотя я не инженер OpenAI, я хочу рассказать о некоторых способах, которыми они, вероятно, работали, чтобы сделать GPT-4 более похожей на модель рассуждений.
Точно так же, как Google стремится к совершенству алгоритмов в поиске, надеясь уйти от человеческого фактора при ранжировании, подобно ссылкам, OpenAI также стремится устранить недостатки моделей LLM.
OpenAI работает двумя способами, чтобы предоставить ChatGPT лучшие возможности «рассуждения»:
- Использование самого GPT или внешних инструментов (например, других алгоритмов машинного обучения).
- Использование других кодовых решений, отличных от LLM.
В первой группе OpenAI настраивает модели друг над другом. На самом деле это разница между ChatGPT и обычным GPT.
Обычный GPT — это механизм, который просто выдает вероятные следующие токены после предложения. С другой стороны, ChatGPT — это модель, обученная командам и следующим шагам.
Одна вещь, которая вызывает недоумение при названии GPT «причудливой автокоррекцией», — это то, как эти слои взаимодействуют друг с другом, и глубокая способность моделей такого размера распознавать шаблоны и применять их в различных контекстах.
Модель способна устанавливать связи между ответами, ожиданиями относительно того, как и контекстуально разные вопросы задаются.
Даже если никто не спрашивал о том, чтобы «объяснить статистику с помощью метафоры о дельфинах», GPT может использовать эти связи по всем направлениям и расширять их. Он знает, как объяснить тему с помощью метафоры, как работает статистика и что такое дельфины.
Однако, как может сказать любой, кто регулярно имеет дело с GPT, чем дальше вы изучаете учебные материалы GPT, тем хуже становится результат.
В OpenAI есть модель, которая обучается на различных уровнях, касающихся:
- Разговоры.
- Избегание любых спорных ответов.
- Держите его в рамках рекомендаций.
Любой, кто пытался заставить GPT действовать за пределами его параметров, может сказать вам, что контекст и команды бесконечно модульны. Люди изобретательны и могут придумывать бесконечные способы нарушения правил.
Все это означает, что OpenAI может обучать LLM «рассуждать», подвергая его слоям рассуждений, чтобы он имитировал и распознавал шаблоны.
Запоминать ответы, не понимая их.
Другой способ, которым OpenAI может добавить возможности рассуждений в свои модели, — это использование других элементов. Но у них есть свой набор проблем. Вы можете видеть, как OpenAI пытается решить проблемы GPT с решениями, отличными от GPT, с помощью плагинов.
Плагин для чтения ссылок предназначен для ChatGPT (GPT-4). Это позволяет пользователю добавлять ссылки в ChatGPT, а агент переходит по ссылке и получает контент. Но как GPT это делает?
Плагин не «думает» и не решает получить доступ к этим ссылкам, а предполагает, что каждая ссылка необходима.
Когда текст анализируется, ссылки посещаются, а HTML выгружается на входе. Сложно более элегантно интегрировать такие плагины.
Например, подключаемый модуль Bing позволяет вам выполнять поиск с помощью Bing, но затем агент предполагает, что вы хотите выполнять поиск гораздо чаще, чем наоборот.
Это связано с тем, что даже при многоуровневом обучении трудно обеспечить последовательные ответы от GPT. Если вы работаете с OpenAI API, это может появиться сразу. Вы можете отметить «как открытую модель ИИ», но некоторые ответы будут иметь другую структуру предложений и другие способы сказать «нет».
Это затрудняет написание ответа механического кода, поскольку он предполагает согласованный ввод.
Если вы хотите интегрировать поиск с приложением OpenAI, какие типы триггеров запускают функцию поиска?
Что, если вы хотите рассказать о поиске в статье? Точно так же фрагментация входных данных может быть затруднена, потому что.
ChatGPT трудно отличить от разных частей подсказки, так как этим моделям трудно отличить фантазию от реальности.
Тем не менее, самый простой способ позволить GPT рассуждать — это интегрировать что-то, что лучше рассуждает. Это все еще легче сказать, чем сделать.
У Райана Джонса была хорошая тема по этому поводу в Твиттере:
Затем мы возвращаемся к вопросу о том, как работают LLM.
Здесь нет ни калькулятора, ни мыслительного процесса, просто угадывание следующего термина на основе огромного массива текста.
Случай 3: GPT против загадок
Мой любимый чехол для такого рода вещей? Детские загадки.
Одно из четырех слов из каждого набора не принадлежит. Какое слово не принадлежит?
- Зеленый, желтый, красный, синий.
- Апрель, декабрь, ноябрь, июнь.
- Перистые, гравийные, кучевые, пластовые.
- Морковь, редис, картофель, капуста.
- Вилка, гребень, грабли, лопата.
Найдите секунду, чтобы подумать об этом. Спросите ребенка.
Вот фактические ответы:
- Зеленый. Желтый, красный и синий являются основными цветами. Зеленый нет.
- Декабрь. В остальных месяцах всего 30 дней.
- Исчисление. Остальные относятся к облачным типам.
- Капуста. Другие овощи, которые растут под землей.
- Лопата. У остальных есть шипы.
Теперь давайте посмотрим на некоторые ответы от GPT:

Что интересно, так это то, что форма этого ответа правильная. Выяснилось, что правильным ответом было «не основной цвет», но контекста было недостаточно, чтобы узнать, что такое основные цвета или что такое цвета.
Это то, что вы могли бы назвать одноразовым запросом. Я не сообщаю модели дополнительных деталей и ожидаю, что она сама разберется во всем. Но, как мы видели в предыдущих ответах, GPT может ошибаться с чрезмерными подсказками.
GPT не умный. Несмотря на то, что он впечатляет, он не такой «универсальный», как хотелось бы.
Он не знает контекста того, что он говорит или делает, и не знает, что такое слово.
Для GPT мир — это математика.
Токены — это просто векторы, танцующие вместе, представляющие сеть в огромном множестве взаимосвязанных точек.
LLM не так умны, как вы думаете
Юрист, который использовал ChatGPT в суде, сказал, что «думал, что это поисковая система».
Это громкое дело о профессиональных злоупотреблениях забавно, но я охвачен страхом перед последствиями.
Эту информацию в суд подал юрист-специалист, занимающийся высококвалифицированной, высокооплачиваемой работой.
По всей стране сотни людей делают то же самое, потому что это почти как поисковая система, кажется человечной и выглядит правильно.
Контент веб-сайта может иметь высокие ставки — все может быть. Дезинформация уже свирепствует в сети, и ChatGPT пожирает то, что осталось.
Мы должны собирать металл с затонувших кораблей, потому что он не был облучен.
Точно так же данные до 2022 года станут ходовым товаром, потому что они проистекают из того, чем должен быть текст — уникальным, человечным и правдивым.
Большая часть такого рода рассуждений, по-видимому, проистекает из нескольких основных причин: непонимания того, как работает GPT, и непонимания того, для чего он используется.
В какой-то степени OpenAI может нести ответственность за эти недоразумения. Они так сильно хотят развивать искусственный общий интеллект, что признать недостатки в том, что может сделать GPT, сложно.
GPT является «хозяином всего» и поэтому не может быть хозяином чего бы то ни было.
Если он не может оскорблять, он не может модерировать контент.
Если оно должно говорить правду, оно не может писать беллетристику.
Если он должен подчиняться пользователю, он не всегда может быть точным.
GPT — это не поисковая система, не чат-бот, не ваш друг, не общий интеллект и даже не модная автозамена.
Это массовая статистика, бросающая кости для составления предложений. Но дело в том, что иногда ты ошибаешься.
Мнения, выраженные в этой статье, принадлежат приглашенному автору, а не обязательно поисковой системе.












Специальная подборка для Вас