Заголовок намеренно вводит в заблуждение, но только в том, что касается использования термина «ChatGPT».
«ChatGPT-подобный» сразу же позволяет вам, читателю, узнать тип технологии, о которой я говорю, вместо того, чтобы описывать систему как «модель генерации текста, подобную GPT-2 или GPT-3». (Кроме того, последний действительно не был бы таким кликабельным…)
В этой статье мы рассмотрим более старую, но очень актуальную статью Google от 2020 года «Генеративные модели — неконтролируемые предикторы качества страницы: исследование колоссального масштаба».
О чем статья?
Начнем с описания авторов. Они вводят тему таким образом:
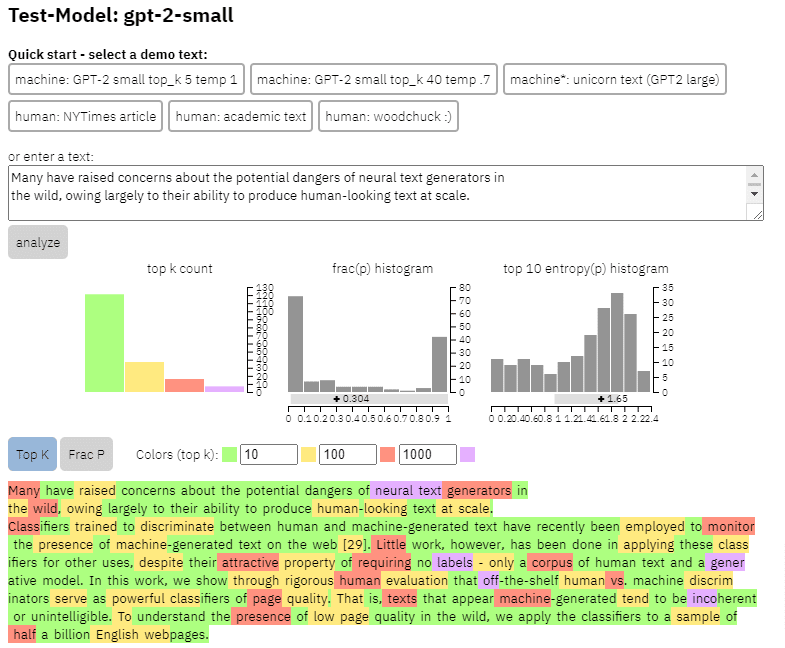
«Многие выражают обеспокоенность по поводу потенциальных опасностей нейронных генераторов текста в дикой природе, в основном из-за их способности создавать человеческий текст в масштабе.
Классификаторы, обученные различать текст, сгенерированный человеком, и текст, сгенерированный машиной, недавно использовались для отслеживания наличия текста, сгенерированного машиной, в Интернете. [29]. Однако было проделано мало работы по применению этих классификаторов для других целей, несмотря на их привлекательное свойство не требовать меток — только корпус человеческого текста и генеративная модель. В этой работе мы показываем с помощью строгой человеческой оценки, что готовые дискриминаторы человека и машины служат мощными классификаторами качества страницы.. То есть тексты, которые кажутся сгенерированными машиной, как правило, бессвязны или неразборчивы. Чтобы понять присутствие низкого качества страниц в дикой природе, мы применяем классификаторы к выборке из полумиллиарда веб-страниц на английском языке».
По сути, они говорят о том, что обнаружили, что те же классификаторы, разработанные для обнаружения копий на основе ИИ, с использованием тех же моделей для их создания, могут быть успешно использованы для обнаружения низкокачественного контента.
Конечно, это оставляет нас с важным вопросом:
Это причинность (т. е. система улавливает это, потому что она действительно хороша в этом) или корреляция (т. е. создается ли большое количество спама таким образом, чтобы его можно было легко обойти с помощью лучших инструментов)?
Прежде чем мы исследуем это, давайте взглянем на некоторые работы авторов и их выводы.
Установка
Для справки, в своем эксперименте они использовали следующее:
- Три набора данных Web500M (случайная выборка из 500 миллионов англоязычных веб-страниц), GPT-2 Output (250 000 текстовых генераций GPT-2) и Grover-Output (внутренне сгенерировано 1,2 млн статей с использованием предварительно обученной модели Grover-Base, предназначенной для обнаружения фейковые новости).
- Базовый уровень спама, классификатор, обученный набору данных Enron Spam Email. Они использовали этот классификатор, чтобы установить номер качества языка, который они будут назначать, поэтому, если модель определяла, что документ не является спамом с вероятностью 0,2, присвоенная оценка качества языка (LQ) составляла 0,2.
Получайте ежедневный информационный бюллетень, на который полагаются поисковые маркетологи.
Немного о распространенности спама
Я хотел бы отвлечься, чтобы обсудить некоторые интересные открытия, на которые наткнулись авторы. Один из них показан на следующем рисунке (рис. 3 из статьи):

Важно обратить внимание на оценку под каждым графиком. Число к 1,0 приближается к уверенности в том, что содержимое является спамом. То, что мы видим, это то, что с 2017 года и далее — и с пиком в 2019 году — преобладали документы низкого качества.
Кроме того, они обнаружили, что влияние некачественного контента в некоторых секторах было выше, чем в других (помните, что более высокий балл отражает более высокую вероятность спама).

Я почесал голову над парой из них. Взрослый имел смысл, очевидно.
А вот книги и литература были чем-то вроде сюрприза. Так было и со здоровьем — пока авторы не назвали виагру и другие сайты о продуктах для здоровья для взрослых «здоровьем», а фермы эссе — «литературой» — то есть.
Их выводы
Помимо того, что мы обсуждали о секторах и всплеске в 2019 году, авторы также обнаружили ряд интересных вещей, из которых оптимизаторы могут извлечь уроки и должны иметь в виду, особенно когда мы начинаем опираться на такие инструменты, как ChatGPT.
- Контент низкого качества, как правило, имеет меньшую длину (максимум 3000 символов).
- Системы обнаружения, обученные определять, был ли текст написан машиной или нет, также хорошо справляются с классификацией контента низкого и высокого уровня.
- Они называют наш контент, предназначенный для ранжирования, конкретным виновником, хотя я подозреваю, что они имеют в виду мусор, который, как мы все знаем, не должен быть там.
Авторы не утверждают, что это окончательное решение, а скорее отправная точка, и я уверен, что за последние пару лет они продвинули планку вперед.
Примечание о контенте, созданном ИИ
Языковые модели также развивались на протяжении многих лет. Хотя GPT-3 существовал на момент написания этой статьи, детекторы, которые они использовали, были основаны на GPT-2, которая является значительно худшей моделью.
GPT-4, скорее всего, не за горами, а Google Sparrow должен быть выпущен в конце этого года. Это означает, что не только технология становится лучше с обеих сторон поля битвы (генераторы контента против поисковых систем), но и комбинации будут легче вводить в игру.
Может ли Google обнаруживать контент, созданный Sparrow или GPT-4? Может быть.
Но как насчет того, чтобы он был сгенерирован с помощью Sparrow, а затем отправлен в GPT-4 с запросом на перезапись?
Еще один фактор, который необходимо помнить, заключается в том, что методы, используемые в этой статье, основаны на авторегрессионных моделях. Проще говоря, они предсказывают счет для слова на основе того, что они предсказывают этому слову, учитывая те, которые ему предшествовали.
По мере того, как модели становятся все более изощренными и начинают создавать полные идеи за один раз, а не одно слово за другим, обнаружение ИИ может дать сбой.
С другой стороны, обнаружение просто дерьмового контента должно усиливаться, что может означать, что единственный «низкокачественный» контент, который выиграет, будет создан искусственным интеллектом.
Мнения, выраженные в этой статье, принадлежат приглашенному автору, а не обязательно поисковой системе. Штатные авторы перечислены здесь.
Подборка статей о ИТ компаниях. Обмен опытом. Обучение востребованным профессиям в сфере IT. Маркетинг. Анализ рынка. Полезная информация. Подпишитесь на нас в социальных сетях, что бы не пропустить важное.








")



Специальная подборка для Вас