В этой статье вы узнаете, как использовать парсинг и Google Knowledge Graph для автоматической разработки подсказок, которая генерирует план и резюме для статьи, которая, если она хорошо написана, будет содержать много ключевых ингредиентов для высокого рейтинга.
По сути, мы говорим GPT-4 создать план статьи на основе ключевого слова и лучших объектов, которые они нашли на выбранной вами странице с высоким рейтингом.
Сущности упорядочены по их показателю значимости.
«Почему показатель значимости?» Вы можете спросить.
Google описывает значимость в своих документах API как:
«Оценка значимости объекта предоставляет информацию о важности или центральном положении этого объекта для всего текста документа. Оценки ближе к 0 менее заметны, а оценки ближе к 1,0 очень заметны».
Кажется довольно хорошей метрикой для влияния на то, какие объекты должны существовать в части контента, который вы, возможно, захотите написать, не так ли?
Начиная
Есть два способа сделать это:
- Потратьте около 5 минут (может быть, 10, если вам нужно настроить компьютер) и запустите скрипты с вашего компьютера, или…
- Перейдите к Colab, который я создал, и начните играть прямо сейчас.
Я неравнодушен к первому, но я также перешел на Colab или два в свой день. ?
Предполагая, что вы все еще здесь и хотите настроить это на своей машине, но еще не установили Python или IDE (интегрированную среду разработки), я сначала направлю вас к быстрому чтению по настройке вашей машины для использования Блокнот Юпитер. Это не должно занимать более 5 минут.
Теперь пришло время идти!
Использование объектов Google и GPT-4 для создания набросков статей
Чтобы упростить понимание, я отформатирую инструкции следующим образом:
- Шаг: Краткое описание шага, на котором мы находимся.
- Код: код для завершения этого шага.
- Объяснение: Краткое объяснение того, что делает код.
Шаг 1: Скажи мне, что ты хочешь
Прежде чем мы углубимся в создание контуров, нам нужно определить, что мы хотим.
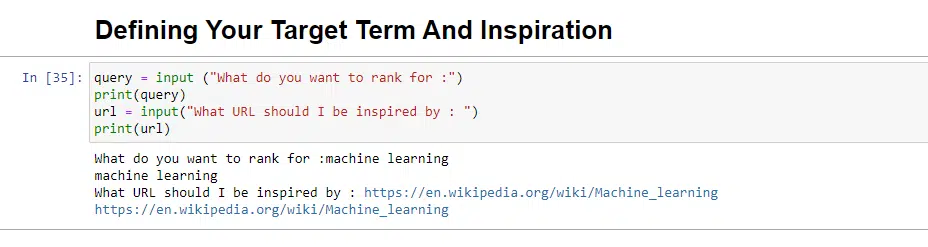
query = input ("What do you want to rank for :")
print(query)
url = input("What URL should I be inspired by : ")
print(url)При запуске этот блок предложит пользователю (возможно, вам) ввести запрос, по которому вы хотите, чтобы статья ранжировалась, а также даст вам место для ввода URL-адреса статьи, которую вы хотите произведение для вдохновения.
Я бы предложил статью, которая хорошо ранжируется, написана в формате, подходящем для вашего сайта, и которая, по вашему мнению, заслуживает ранжирования только по ценности статьи, а не только по силе сайта.
При запуске это будет выглядеть так:
Шаг 2: Установка необходимых библиотек
Затем мы должны установить все библиотеки, которые мы будем использовать, чтобы волшебство произошло.
!pip install google-cloud-language beautifulsoup4 openai
!pip install wandb --upgrade
!pip install --force-reinstall -Iv protobuf==3.20.00
import requests
import json
from bs4 import BeautifulSoup
from google.cloud import language_v1
from google.oauth2 import service_account
import os
import openai
import pandas as pd
import wandbМы устанавливаем следующие библиотеки:
- Запросы: эта библиотека позволяет выполнять HTTP-запросы для получения контента с веб-сайтов или веб-API.
- JSON: он предоставляет функции для работы с данными JSON, включая синтаксический анализ строк JSON в объекты Python и сериализацию объектов Python в строки JSON.
- КрасивыйСуп: эта библиотека используется для очистки веб-страниц. Это помогает анализировать и перемещаться по документам HTML или XML и извлекать из них соответствующую информацию.
- Google.cloud.language_v1: это библиотека из Google Cloud, которая предоставляет возможности обработки естественного языка. Это позволяет выполнять различные задачи, такие как анализ настроений, признание сущностии синтаксический анализ текстовых данных.
- Google.oauth2.service_account: эта библиотека является частью пакета Google OAuth2 Python. Он обеспечивает поддержку аутентификации с помощью API Google с использованием служебной учетной записи, что позволяет предоставить ограниченный доступ к ресурсам проекта Google Cloud.
- Операционные системы: эта библиотека предоставляет способ взаимодействия с операционной системой. Он позволяет получить доступ к различным функциям, таким как операции с файлами, переменные среды и управление процессами.
- OpenAI: эта библиотека представляет собой пакет OpenAI Python. Он предоставляет интерфейс для взаимодействия с языковыми моделями OpenAI, включая GPT-4 (и 3). Это позволяет разработчикам генерировать текст, выполнять завершение текста и многое другое.
- Панды: это мощная библиотека для обработки и анализа данных. Он предоставляет структуры данных и функции для эффективной обработки и анализа структурированных данных, таких как таблицы или файлы CSV.
- ЖезлБ: эта библиотека расшифровывается как «Weights & Biases» и представляет собой инструмент для отслеживания и визуализации экспериментов. Он помогает регистрировать и визуализировать метрики, гиперпараметры и другие важные аспекты экспериментов по машинному обучению.
При запуске это выглядит так:

Получайте ежедневный информационный бюллетень, на который полагаются поисковые маркетологи.
Шаг 3: Аутентификация
Мне придется отвлечь нас на мгновение, чтобы отвлечься и установить нашу аутентификацию. Нам понадобится ключ API OpenAI и учетные данные Google Knowledge Graph Search.
Это займет всего несколько минут.
Получение вашего OpenAI API
В настоящее время вам, вероятно, нужно присоединиться к списку ожидания. Мне повезло, что у меня есть доступ к API на раннем этапе, и поэтому я пишу это, чтобы помочь вам настроить его, как только вы его получите.
Изображения для регистрации взяты из GPT-3 и будут обновлены для GPT-4, как только поток станет доступен для всех.
Прежде чем вы сможете использовать GPT-4, вам понадобится ключ API для доступа к нему.
Чтобы получить его, просто перейдите на страницу продукта OpenAI и нажмите Начать.

Выберите способ регистрации (я выбрал Google) и пройдите процесс проверки. Для этого шага вам понадобится доступ к телефону, который может принимать текстовые сообщения.
После этого вы создадите ключ API. Это сделано для того, чтобы OpenAI мог подключить ваши скрипты к вашей учетной записи.
Они должны знать, кто чем занимается, и определять, должны ли и сколько они должны брать с вас плату за то, что вы делаете.
Цены OpenAI
После регистрации вы получаете кредит в размере 5 долларов, который поможет вам на удивление далеко, если вы просто экспериментируете.
На момент написания этой статьи ценообразование в прошлом было следующим:

Создание ключа OpenAI
Чтобы создать свой ключ, нажмите на свой профиль в правом верхнем углу и выберите Просмотр ключей API.

…и затем вы создадите свой ключ.
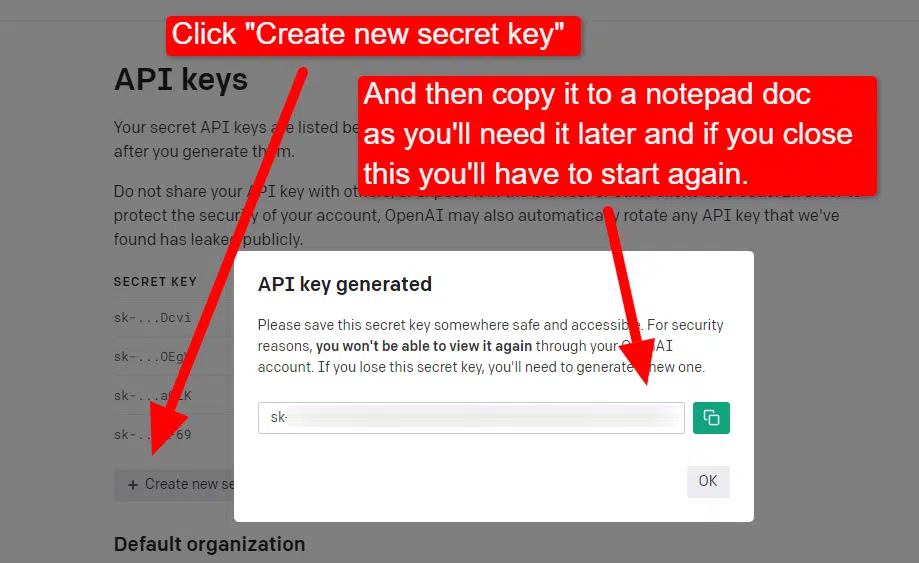
Как только вы закроете лайтбокс, вы не сможете просмотреть свой ключ, и вам придется создать его заново, поэтому для этого проекта просто скопируйте его в документ «Блокнот», чтобы использовать его в ближайшее время.
Примечание: Не сохраняйте свой ключ (документ Блокнота на вашем рабочем столе не очень безопасен). После того, как вы использовали его на мгновение, закройте документ «Блокнот», не сохраняя его.
Получение аутентификации Google Cloud
Во-первых, вам нужно войти в свою учетную запись Google. (Вы находитесь на SEO-сайте, поэтому я предполагаю, что он у вас есть. ?)
Сделав это, вы можете просмотреть информацию об API сети знаний, если хотите, или сразу перейти к консоли API и приступить к работе.
Как только вы окажетесь за консолью:
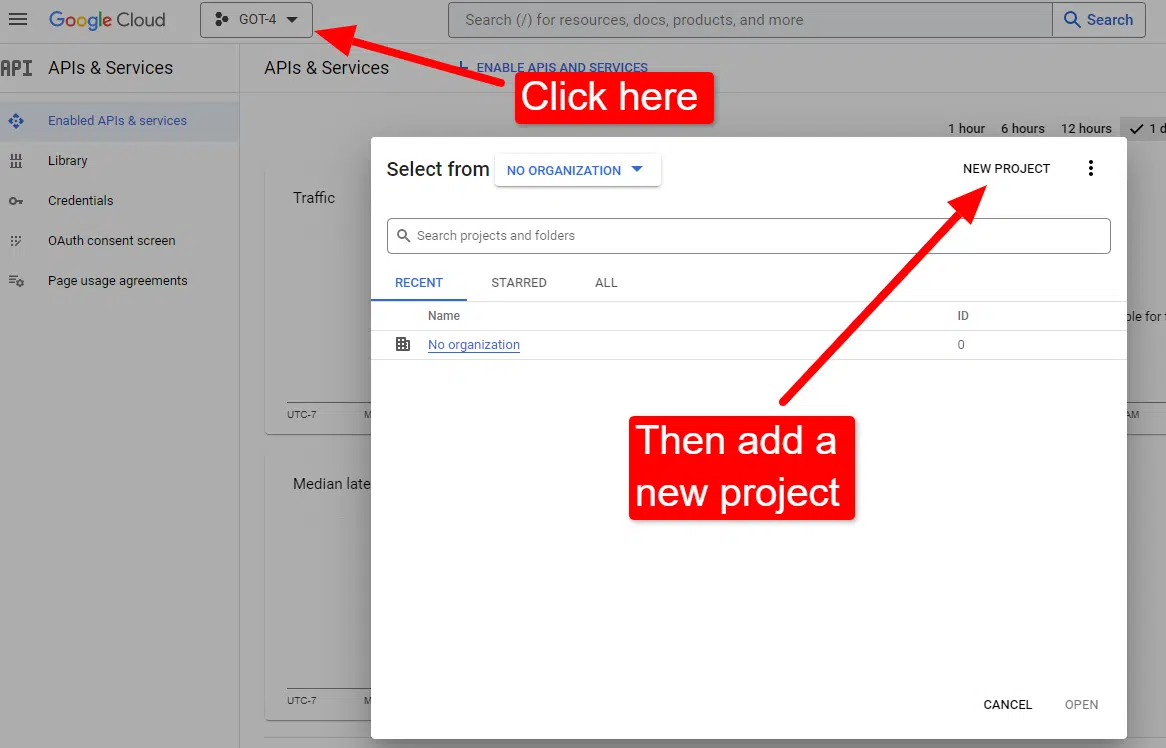
Назовите это что-то вроде «Потрясающие статьи Дэйва». Знаете… легко запомнить.
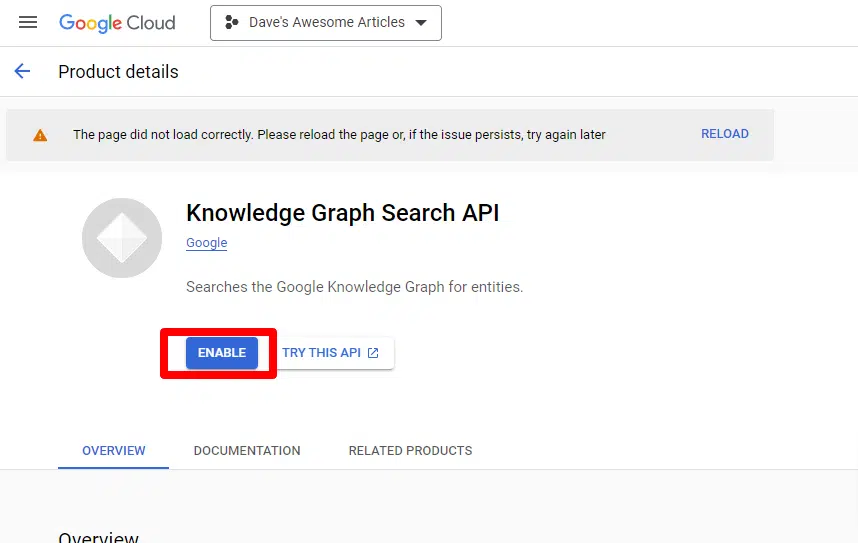
Затем вы включите API, нажав Включить API и сервисы.

Найдите API поиска сети знаний и включите его.
Затем вы вернетесь на главную страницу API, где сможете создать учетные данные:

И мы создадим сервисный аккаунт.

Просто создайте учетную запись службы:

Заполните необходимую информацию:

(Вам нужно будет дать ему имя и предоставить права владельца.)
Теперь у нас есть наш сервисный аккаунт. Осталось создать наш ключ.
Нажмите на три точки под Действия и нажмите Управление ключами.

Нажмите Добавить ключ затем Создать новый ключ:

Тип ключа будет JSON.
Сразу же вы увидите, что он загружается в папку загрузки по умолчанию.
Этот ключ предоставит доступ к вашим API, поэтому держите его в безопасности, как и ваш API OpenAI.
Хорошо… и мы вернулись. Готовы продолжить наш сценарий?
Теперь, когда они у нас есть, нам нужно определить наш ключ API и путь к загруженному файлу. Код для этого:
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/PATH-TO-FILE/FILENAME.JSON'
%env OPENAI_API_KEY=YOUR_OPENAI_API_KEY
openai.api_key = os.environ.get("OPENAI_API_KEY")Вы замените YOUR_OPENAI_API_KEY со своим ключом.
Вы также замените /PATH-TO-FILE/FILENAME.JSON с путем к ключу учетной записи службы, который вы только что скачали, включая имя файла.
Запустите ячейку, и вы готовы двигаться дальше.
Шаг 4: Создайте функции
Далее мы создадим функции для:
- Очистите веб-страницу, которую мы ввели выше.
- Проанализируйте содержимое и извлеките сущности.
- Создайте статью с помощью GPT-4.
#The function to scrape the web page
def scrape_url(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
paragraphs = soup.find_all("p")
text = " ".join([p.get_text() for p in paragraphs])
return text#The function to pull and analyze the entities on the page using Google's Knowledge Graph API
def analyze_content(content):
client = language_v1.LanguageServiceClient()
response = client.analyze_entities(
request={"document": language_v1.Document(content=content, type_=language_v1.Document.Type.PLAIN_TEXT), "encoding_type": language_v1.EncodingType.UTF8}
)
top_entities = sorted(response.entities, key=lambda x: x.salience, reverse=True)[:10]
for entity in top_entities:
print(entity.name)
return top_entities#The function to generate the content
def generate_article(content):
openai.api_key = os.environ["OPENAI_API_KEY"]
response = openai.ChatCompletion.create(
messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."},
{"role": "user", "content": content}],
model="gpt-4",
max_tokens=1500, #The maximum with GPT-3 is 4096 including the prompt
n=1, #How many results to produce per prompt
#best_of=1 #When n>1 completions can be run server-side and the "best" used
stop=None,
temperature=0.8 #A number between 0 and 2, where higher numbers add randomness
)
return response.choices[0].message.content.strip()Это примерно то, что описывают комментарии. Мы создаем три функции для целей, изложенных выше.
Зоркие глаза заметят:
сообщения = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."},You can edit the content (You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well.) and describe the role you want ChatGPT to take. You can also add tone (e.g., “You are a friendly writer …”).
Step 5: Scrape the URL and print the entities
Now we’re getting our hands dirty. It’s time to:
- Scrape the URL we entered above.
- Pull all the content that lives within paragraph tags.
- Run it through Google Knowledge Graph API.
- Output the entities for a quick preview.
Basically, you want to see anything at this stage. If you see nothing, check a different site.
content = scrape_url(url)
entities = analyze_content(content)You can see that line one calls the function that scrapes the URL we first entered. The second line analyzes the content to extract the entities and key metrics.
Part of the analyze_content function also prints a list of the entities found for quick reference and verification.
Step 6: Analyze the entities
When I first started playing around with the script, I started with 20 entities and quickly discovered that’s usually too many. But is the default (10) right?
To find out, we’ll write the data to W&B Tables for easy assessment. It’ll keep the data indefinitely for future evaluation.
First, you’ll need to take about 30 seconds to sign up. (Don’t worry, it’s free for this type of thing!) You can do so at
Once you’ve done that, the code to do this is:
run = wandb.init(project="Article Summary With Entities")
columns=["Name", "Salience"]
ent_table = wandb.Table(columns=columns) для сущности в сущностях: ent_table.add_data(entity.name, entity.salience) run.log({"Таблица сущностей": ent_table}) wandb.finish()При запуске вывод выглядит следующим образом:
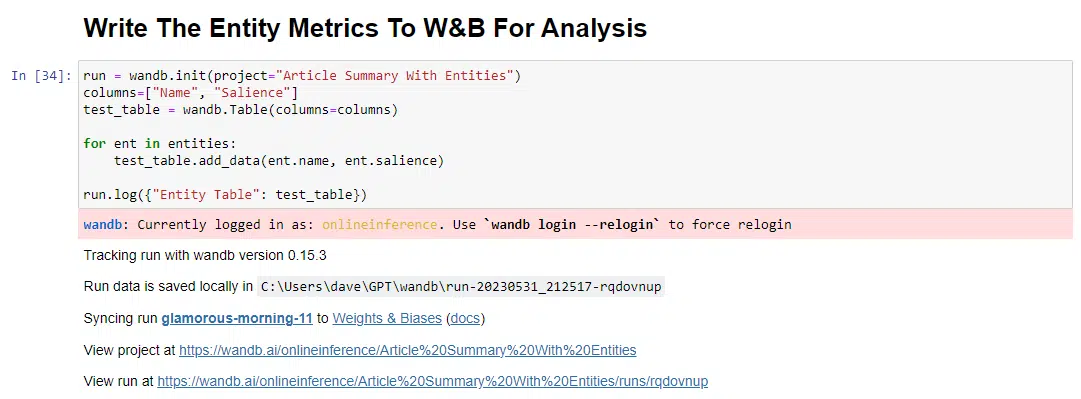
И когда вы нажмете на ссылку, чтобы просмотреть свой пробег, вы найдете:

Вы можете увидеть снижение показателя значимости. Помните, что эта оценка рассчитывает, насколько важен этот термин для страницы, а не для запроса.
При просмотре этих данных вы можете настроить количество сущностей на основе значимости или только тогда, когда вы видите всплывающие нерелевантные термины.
Чтобы настроить количество сущностей, вы должны перейти в ячейку функций и отредактировать:

Затем вам нужно будет снова запустить ячейку и ту, которую вы запустили, чтобы очистить и проанализировать содержимое, чтобы использовать новое количество сущностей.
Шаг 7: Создайте план статьи
Момент, которого вы все ждали, пришло время создать схему статьи.
Это делается в двух частях. Во-первых, нам нужно сгенерировать приглашение, добавив ячейку:
entity_names = [entity.name for entity in entities]
gpt_prompt = f"Create an outline for an article about {query} that includes the following entities: {', '.join(entity_names)}."
print(gpt_prompt)По сути, это создает подсказку для создания статьи:

И затем все, что осталось, это создать план статьи, используя следующее:
generated_article = generate_article(gpt_prompt)
print(generated_article)Что будет производить что-то вроде:

И если вы также хотите получить письменное резюме, вы можете добавить:
gpt_prompt2 = f"Write an article summary about {query} for an article with an outline of: {generated_article}."
generated_article = generate_article(gpt_prompt2)
print(generated_article)Что будет производить что-то вроде:

Мнения, выраженные в этой статье, принадлежат приглашенному автору, а не обязательно поисковой системе. Штатные авторы перечислены здесь.
Подборка статей о ИТ компаниях. Обмен опытом. Обучение востребованным профессиям в сфере IT. Маркетинг. Анализ рынка. Полезная информация. Подпишитесь на нас в социальных сетях, что бы не пропустить важное.












Специальная подборка для Вас