Googlebot — это автоматическая и постоянно работающая система веб-сканирования, которая поддерживает обновление индекса Google.
Веб-сайт worldwebsize.com оценивает индекс Google более чем в 62 миллиарда веб-страниц.
Поисковый индекс Google «весит более 100 000 000 гигабайт».
Googlebot и его варианты (смартфоны, новости, изображения и т. д.) имеют определенные ограничения на частоту рендеринга JavaScript или размер ресурсов.
Google использует ограничения сканирования для защиты собственных ресурсов и систем сканирования.
Например, если новостной веб-сайт обновляет рекомендуемые статьи каждые 15 секунд, робот Googlebot может начать пропускать часто обновляемые разделы, поскольку через 15 секунд они перестанут быть актуальными или действительными.
Несколько лет назад Google объявил, что не сканирует и не использует ресурсы размером более 15 МБ.
28 июня 2022 г. Google повторно опубликовал это сообщение в блоге, заявив, что не использует лишнюю часть ресурсов после 15 МБ для сканирования.
Чтобы подчеркнуть, что такое случается редко, Google заявил, что «средний размер HTML-файла в 500 раз меньше», чем 15 МБ.
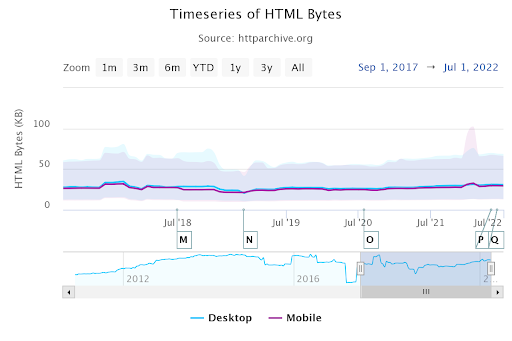 Скриншот от автора, август 2022 г.
Скриншот от автора, август 2022 г.Выше HTTPArchive.org показывает средний размер HTML-файла для ПК и мобильных устройств. Таким образом, у большинства веб-сайтов нет проблемы ограничения 15 МБ для сканирования.
Но сеть — это большое и хаотичное место.
Понимание природы ограничения сканирования в 15 МБ и способов его анализа важно для SEO-специалистов.
Изображение, видео или ошибка могут вызвать проблемы со сканированием, и эта малоизвестная SEO-информация может помочь проектам защитить свою ценность в органическом поиске.

Является ли ограничение сканирования Googlebot 15 МБ только для документов HTML?
Нет.
Ограничение сканирования Googlebot 15 МБ для всех индексируемых и доступных для сканирования документов, включая Google Earth, Hancom Hanword (.hwp), текст OpenOffice (.odt) и Rich Text Format (.rtf) или другие типы файлов, поддерживаемые роботом Googlebot.
Суммируются ли размеры изображений и видео с HTML-документом?
Нет, каждый ресурс оценивается отдельно по лимиту обхода в 15 МБ.
Если размер HTML-документа составляет 14,99 МБ, а рекомендуемое изображение HTML-документа снова имеет размер 14,99 МБ, они оба будут просканированы и использованы роботом Googlebot.
Размер документа HTML не суммируется с ресурсами, связанными тегами HTML.
Встроенные CSS, JS или Data URI увеличивают размер HTML-документа?
Да, встроенные CSS, JS или URI данных учитываются и используются в размере HTML-документа.
Таким образом, если размер документа превышает 15 МБ из-за встроенных ресурсов и команд, это повлияет на возможность сканирования конкретного HTML-документа.
Прекращает ли Google сканировать ресурс, если он больше 15 МБ?
Нет, системы сканирования Google не прекращают сканирование ресурсов, размер которых превышает ограничение в 15 МБ.
Они продолжают извлекать файл и используют только меньшую часть, чем 15 МБ.
Для изображения размером более 15 МБ робот Googlebot может разбить изображение до размера 15 МБ с помощью «диапазона контента».
Content-Range — это заголовок ответа, который помогает роботу Googlebot или другим поисковым роботам и запрашивающим сторонам выполнять частичные запросы.
Как проверить размер ресурса вручную?
Вы можете использовать инструменты разработчика Google Chrome для проверки размера ресурса вручную.
Выполните следующие действия в Google Chrome.
- Откройте документ веб-страницы через Google Chrome.
- Нажмите F12.
- Перейдите на вкладку Сеть.
- Обновите веб-страницу.
- Расположите ресурсы в соответствии с Водопадом.
- Проверить размер столбец в первой строке, который показывает размер HTML-документа.
Ниже вы можете увидеть пример HTML-документа главной страницы searchenginejournal.com, размер которого превышает 77 КБ.
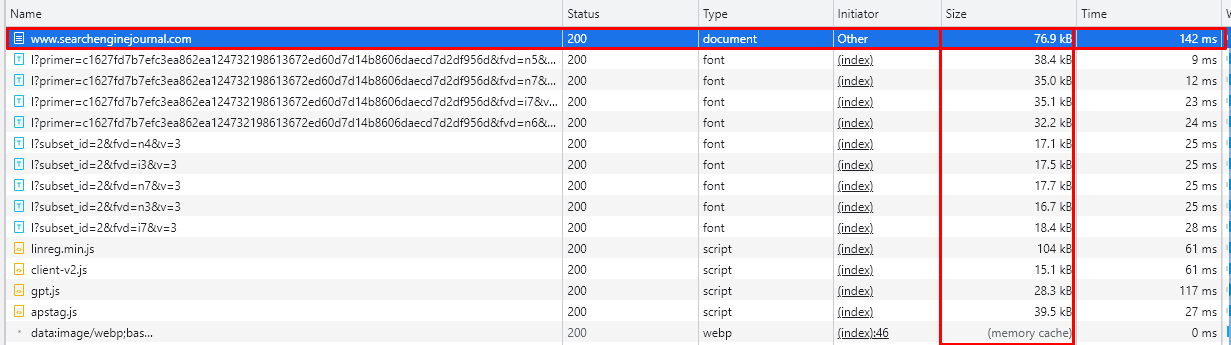 Скриншот автора, август 2022 г.
Скриншот автора, август 2022 г.Как автоматически и массово проверять размер ресурсов?
Используйте Python для автоматического и массового аудита размера HTML-документа. Advertools и Pandas — две полезные библиотеки Python для автоматизации и масштабирования задач SEO.
Следуйте приведенным ниже инструкциям.
- Импорт рекламных инструментов и панд.
- Соберите все URL-адреса в карте сайта.
- Просканируйте все URL-адреса в карте сайта.
- Отфильтруйте URL-адреса по их размеру HTML.
import advertools as adv
import pandas as pd
df = adv.sitemap_to_df("
adv.crawl(df["loc"], output_file="output.jl", custom_settings={"LOG_FILE":"output_1.log"})
df = pd.read_json("output.jl", lines=True)
df[["url", "size"]].sort_values(by="size", ascending=False)Приведенный выше блок кода извлекает URL-адреса карты сайта и сканирует их.
Последняя строка кода предназначена только для создания фрейма данных в порядке убывания на основе размеров.
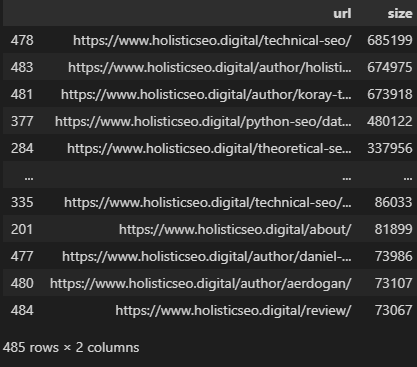 Изображение создано автором, август 2022 г.
Изображение создано автором, август 2022 г.Вы можете увидеть размеры HTML-документов, как указано выше.
Самый большой HTML-документ в этом примере имеет размер около 700 КБ и является страницей категории.
Таким образом, этот веб-сайт безопасен для ограничений в 15 МБ. Но мы можем проверить помимо этого.
Как проверить размеры ресурсов CSS и JS?
Puppeteer используется для проверки размера ресурсов CSS и JS.
Puppeteer — это пакет NodeJS для управления Google Chrome в автономном режиме для автоматизации браузера и тестирования веб-сайтов.
Большинство SEO-специалистов используют Lighthouse или Page Speed Insights API для своих тестов производительности. Но с помощью Puppeteer можно проанализировать каждый технический аспект и симуляцию.
Следуйте блоку кода ниже.
const puppeteer = require('puppeteer');
const XLSX = require("xlsx");
const path = require("path");
(async () => {
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
await page.goto('
console.log('Page loaded');
const perfEntries = JSON.parse(
await page.evaluate(() => JSON.stringify(performance.getEntries()))
);
console.log(perfEntries);
const workSheetColumnName = [
"name",
"transferSize",
"encodedSize",
"decodedSize"
]
const urlObject = new URL("
const hostName = urlObject.hostname
const domainName = hostName.replace("\www.|.com", "");
console.log(hostName)
console.log(domainName)
const workSheetName = "Users";
const filePath = `./${domainName}`;
const userList = perfEntries;
const exportPerfToExcel = (userList) => {
const data = perfEntries.map(url => {
return [url.name, url.transferSize, url.encodedBodySize, url. decodedBodySize];
})
const workBook = XLSX.utils.book_new();
const workSheetData = [
workSheetColumnName,
...data
]
const workSheet = XLSX.utils.aoa_to_sheet(workSheetData);
XLSX.utils.book_append_sheet(workBook, workSheet, workSheetName);
XLSX.writeFile(workBook, path.resolve(filePath));
return true;
}
exportPerfToExcel(userList)
//browser.close();
})();Если вы не знаете JavaScript или не прошли какое-либо руководство по Puppeteer, вам может быть немного сложнее понять эти блоки кода. Но на самом деле это просто.
По сути, он открывает URL-адрес, берет все ресурсы и выдает их «transferSize», «encodedSize» и «decodedSize».
В этом примере «decodedSize» — это размер, на котором нам нужно сосредоточиться. Ниже вы можете увидеть результат в виде файла XLS.
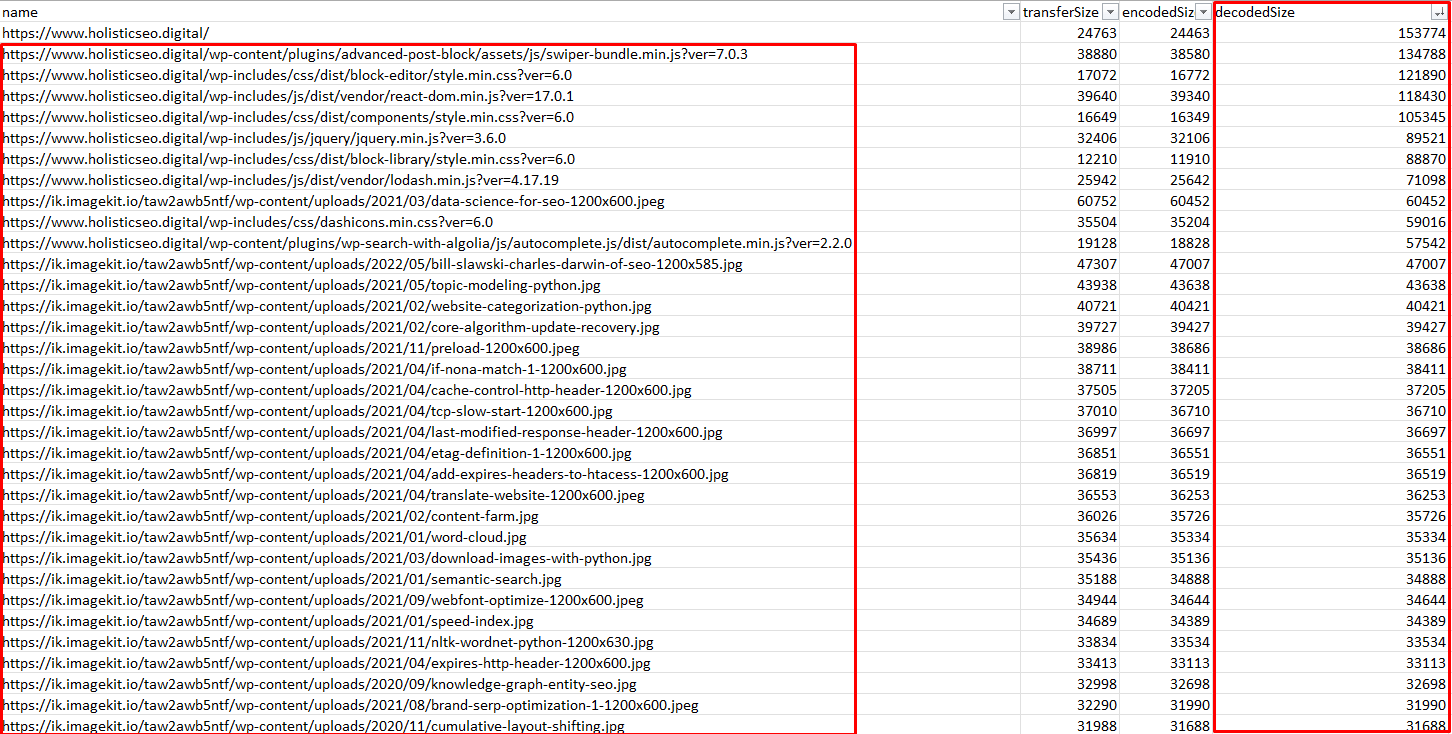 Размер ресурсов с сайта в байтах.
Размер ресурсов с сайта в байтах.Если вы хотите снова автоматизировать эти процессы для каждого URL-адреса, вам нужно будет использовать цикл for в команде «await.page.goto()».
В соответствии с вашими предпочтениями вы можете поместить каждую веб-страницу на отдельный рабочий лист или прикрепить ее к тому же рабочему листу, добавив его.
Вывод
Ограничение сканирования Googlebot в 15 МБ — это редкая возможность, которая на данный момент заблокирует ваши технические SEO-процессы, но HTTPArchive.org показывает, что средний размер видео, изображений и JavaScript увеличился за последние несколько лет.
Средний размер изображения на рабочем столе превысил 1 МБ.
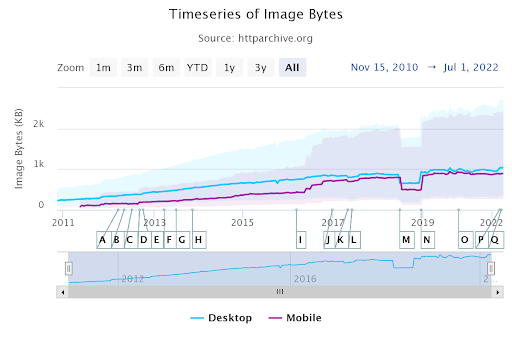 Скриншот автора, август 2022 г.
Скриншот автора, август 2022 г.Общий размер байтов видео превышает 5 МБ.
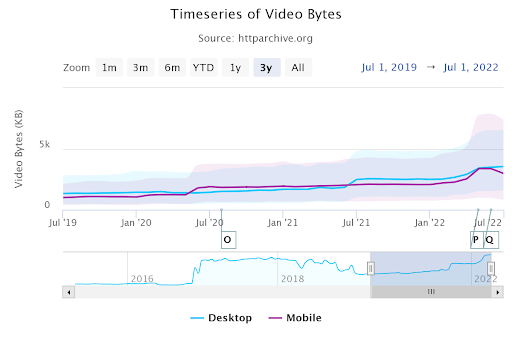 Скриншот автора, август 2022 г.
Скриншот автора, август 2022 г.Другими словами, время от времени эти ресурсы или некоторые их части могут быть пропущены роботом Googlebot.
Таким образом, вы должны иметь возможность контролировать их автоматически с помощью массовых методов, чтобы успеть и не пропустить.
Дополнительные ресурсы:
Рекомендуемое изображение: BestForBest/Shutterstock
Самое время подумать о том, как прокачать себя и своих работников. Освоить новую профессию, повысить уровень квалификации, занять высокооплачиваемую должность. Вы сможете увеличить свою прибыль многократно. Все в Ваших руках!
Стать Digital профессионалом.Подборка статей по SEO оптимизации сайта. Выбора стратегии продвижения. Продвижение сайта в поисковых системах и социальных сетях. Обучение востребованным профессиям в сфере IT. Настройка рекламных кампаний в интернет. Маркетинг. Анализ рынка. Полезные секреты проведения рекламных кампаний. Все для PR — менеджера.












Специальная подборка для Вас